十诫
来自<the little schemer>
The First Commandment
When recurring on a list of atoms, lat, ask two questions about it: (null? lat) and else.
When recurring on a number, n, ask two questions about it: (zero? n) and else.
When recurring on a list of S-expressions, l,ask three question about it: (null? l), (atom?(car l)), and else.
The Second Commandment
Use cons to build lists.
The Third Commandment
When building a list, describe the first typical element, and then cons it onto the natural recursion.
The Fourth Commandment
Always change at least one argument while recurring.
When recurring on a list of atoms,lat,use (cdr lat).
When recurring on a num .ber, n, use (sub1 n).
And when recurring on a list of S-expressions, l, use (car l) and (cdr l) if neither (null? l) nor (atom? (car l)) are true.
It must be changed to be closer to termination. The changing argument must be tested in the termination condition:
when using test termination with cdr, test termination with null?
and when using sub1, test termination with zero?.
The Fifth Commandment
When building a value with + ,always use 0 for the value of the terminating line, for adding 0 does not change the value of an addition.
When building a value with x, always use 1 for the value of the terminating line, for multiplying by 1 does not change the value of a multiplication.
When building a value with cons, always consider '() for the value of the terminating line.
The Sixth Commandment
Simplify only after the function is correct.
The Seventh Commandment
Recur on the subparts that are of the same nature:
• On the sublists of a list.
• On the subexpressions of an arithmetic expression.
The Eighth Commandment
Use help functions to abstract from representations.
The Ninth Commandment
Abstract common patterns with a new function.
The Tenth Commandment
Build functions to collect more than one value at a time.
尾递归改写为递归
做备忘用.
上代码
#lang racket
;;factorial
;;non-tail recursion
(define (fact1 n)
(if (= 0 n)
1
(* n (fact1 (- n 1)))))
;;factorial
;;tail recursion
(define (fact-aux n result)
(if (= 0 n)
result
(fact-aux (- n 1)(* n result))))
(define (fact2 n)
(fact-aux n 1))
(define (fact3 n)
(let fact-aux ([s n][result 1])
(if (= 0 s)
result
(fact-aux (- s 1)(* s result)))))
;;fibonacci
;;non-tail recursion
(define (fib1 n)
(if (< n 2)
n
(+ (fib1 (- n 1))(fib1 (- n 2)))))
;;fibonacci
;; tail recursion
(define (fib-aux n next result)
(if (= n 0)
result
(fib-aux (- n 1) (+ next result) next)))
(define (fib2 n)
(fib-aux n 1 0))
(define (fib3 n)
(define (fib-aux n next result)
(if (= 0 n)
result
(fib-aux (- n 1) (+ next result) next)))
(fib-aux n 1 0))
when converting recursive functions to tail recursive funcion.add a auxiliary parameter.
ps. python 没有尾递归优化.
lisp系有.解释器自动将尾递归转化为迭代.
参考:
http://www.csee.umbc.edu/~chang/cs202.f98/readings/recursion.html
[scheme学习笔记]二叉树的遍历
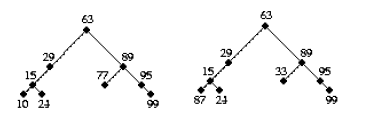
(define BT1 (make-node 63 'a
(make-node 29 'b
(make-node 15 'c
(make-node 10 'd false false)
(make-node 24 'e false false)) false)
(make-node 89 'f
(make-node 77 'g false false)
(make-node 95 'h false
(make-node 99 'i false false)))))
(define BT2 (make-node 63 'a
(make-node 29 'b
(make-node 15 'c
(make-node 87 'd false false)
(make-node 24 'e false false)) false)
(make-node 89 'f
(make-node 33 'g false false)
(make-node 95 'h false
(make-node 99 'i false false)))))

;;inorder:BT->list
(define (inorder BT)
(cond
((boolean? BT) empty)
(else
(append
(inorder (node-left BT))
(list (node-ssn BT))
(inorder (node-right BT))))))
(define (preorder BT)
(cond
((boolean? BT) empty)
(else
(append
(list(node-ssn BT))
(preorder (node-left BT))
(preorder (node-right BT))))))
(define (postorder BT)
(cond
((boolean? BT) empty)
(else
(append
(postorder (node-left BT))
(postorder (node-right BT))
(list(node-ssn BT))))))
[scheme学习笔记]scheme中的快速排序和合并排序
;;filter:listX-listX
(define (filter pred list)
(cond
((empty? list) list)
(else (cond
((pred (car list))
(cons (car list) (filter pred (cdr list))))
(else (pred (cdr list)))))))
(define (q-sort lst)
(if (null? lst)
lst
(append (q-sort (filter (lambda (x) (<= x (car lst))) (cdr lst)))
(list (car lst))
(q-sort (filter (lambda (x) (> x (car lst))) (cdr lst))))))
;;merge-sort:list->list
(define (merge-sort x)
(define (merge-sort-worker x)
(if (= (length x) 1)
(car x)
(merge-sort-worker (merge-all-neighbors x))))
(merge-sort-worker (make-singles x)))
;;make-singles:alon-> lists of number
(define (make-singles alon)
(cond
((empty? alon) empty)
(else (cons(cons (first alon) empty) (make-singles (rest alon))))))
;;merge-all-neighbors:lists->list
(define (merge-all-neighbors alist)
(cond
((empty? alist) empty)
((empty? (rest alist)) empty)
(else (cons (sort (append (first alist)(second alist))<)(merge-all-neighbors (rest (rest alist)))))))
另..
how to design programs中文版下载地址
ftp://ftp.cs.sjtu.edu.cn:990/huanglp/程序设计方法/如何设计程序.PDF
[转]Scheme 之道 --- 无处不在的函数
原文链接:http://hi.baidu.com/pudding/blog/item/7029c8fc45c046fdfc037f2e.html
无处不在的函数
基本的函数概念
Scheme 是一门函数式语言, 因为它的函数与数据有完全平等的地位, 它可以在运行时被实时创建和修改. 也因为它的全部运行都可以用函数的方式来解释, 莫能例外.
比方说, 把 if 语句作为函数来解释? (if cond if-part else-part) 是这么一个特殊的函数: 它根据 cond 是否为真, 决定执行并返回 if-part 还是 else-part. 比如, 我可以这样写:
((if (i-am-feeling-lucky) + -) my-happyness 1)
if 函数会根据我开心与否 (i-am-feeling-lucky 是一个由我决定它的返回值的函数 :P) 返回 + 或 - 来作为对我的开心值的操作. 所谓无处不在的函数, 其意义大抵如此.
把一串操作序列当成函数呢? Scheme 是没有 "return" 的, 把一串操作序列当作一个整体, 它的返回值就是这一串序列的最后一个的返回值. 比如我们可以写
(begin (+ 1 2) (+ 3 4))
它的返回是 7.
无名的能量之源
接下来, 我们就要接触到 Scheme 的灵魂 --- Lambda. 大家可以注意到 drScheme 的图标, 那就是希腊字母 Lambda. 可以说明 Lambda 运算在 Scheme 中是多么重要.
NOTE: 这里本来应该插一点 Lambda 运算的知识的, 但是一来我自己数学就不怎么好没什么信心能讲好, 二来讲太深了也没有必要. 大家如果对 Lambda 运算的理论有兴趣的话, 可以自行 Google 相关资料.
Lambda 能够返回一个匿名的函数. 在这里需要注意两点: 第一, 我用的是 "返回" 而不是 "定义". 因为 Lambda 同样可以看成一个函数 --- 一个能够生成函数的函数. 第二, 它是匿名的, 意思是, 一个函数并不一定需要与一个名字绑定在一起, 我们有时侯需要这么干, 但也有很多时候不需要.
我们可以看一个 Lambda 函数的基本例子:
((lambda (x y) (+ x y)) 1 2)
这里描述了一个加法函数的生成和使用. (lambda (x y) (+ x y)) 中, lambda 的第一个参数说明了参数列表, 之后的描述了函数的行为. 这就生成了一个函数 , 我们再将 1 和 2 作用在这个函数上, 自然能得到结果 3.
我们先引入一个 define 的操作, define 的作用是将一个符号与一个对象绑定起来. 比如 (define name 'kyhpudding) 之后再敲入 name, 这时候 Scheme 解释器就知道如何处理它了, 它会返回一个 kyhpudding.
我们自然也可以用 define 把一个符号和函数绑定在一起, 就得到了我们常用的有名函数.
(define add
(lambda (x y) (+ x y)))
做一个简单的替换, 上面的例子就可以写成 (add 1 2), 这样就好理解多了.
上面的写法有点晦涩, 而我们经常用到的是有名函数, 所以我们有一个简单的写法, 我们把这一类简化的写法叫 "语法糖衣". 在前面我们也遇到一例, 将 (quote x) 写成 'x 的例子. 上面的定义, 我们可以这样写
(define (add x y) (+ x y))
Lambda 运算有极其强大的能力, 上面只不过是用它来做传统的 "定义函数" 的工作. 它的能力远不止如此. 这里只是举几个小小的例子:
我们经常会需要一些用于迭代的函数, 比如这个:
(define (inc x) (+ x 1))
我们也需要减的, 乘的, 还有其他各种乱七八糟的操作, 我们需要每次迭代不是 1, 而是 2, 等等等等. 我们很自然地有这个想法: 我们写个函数来生成这类迭代函数如何? 在 Scheme 中, 利用 lambda 运算, 这是可行且非常简单的. 因为在 Scheme 中, 函数跟普通对象是有同样地位的, 而 "定义" 函数的 lambda, 其实是能够动态地为我们创造并返回函数对象的. 所以我们可以这么写:
(define (make-iterator method step)
(lambda (x) (method x step)))
没有语法糖衣的写法是:
(define make-iterator
(lambda (method step)
(lambda (x) (method x step))))
这个简单的例子, 已经能够完成我们在 C 之类的语言无法完成的事情. 要生成上面的 inc 函数, 我们可以这么写:
(define inc (make-iterator + 1))
这个例子展示的是 Scheme 利用 Lambda 运算得到的能力. 利用它, 我们可以写出制造函数的函数, 或者说制造机器的机器, 这极大地扩展了这门语言的能力 . 我们在以后会有更复杂的例子.
接下来, 我们会介绍 Scheme 的一些语言特性是怎么用 Lambda 运算实现的 --- 说Scheme 的整个机制是由 Lambda 驱动的也不为过.
比如, 在 Scheme 中我们可以在任何地方定义 "局部变量", 我们可以这么写:
(let ((x 1) (y 2)) 运用这些局部变量的语句)
其实 let 也只不过是语法糖衣而已, 因为上面的写法等价于:
((lambda (x y)
运用这些局部变量的语句)
1 2)
一些常用的函数
虽然说这篇文章不太注重语言的实用性. 但这里还是列出我们经常用到的一些操作,这能极大地方便我们的编程, 大家也可以想想他们是怎么实现的.
- cond
相当于 C 中的 switch
(cond
(条件1 执行体)
(条件2 执行体)
(else 执行体))
- 循环语句
没有循环语句...... 至少没有必要的循环语句. Scheme 认为, 任何的循环迭代都
可以用递归来实现. 我们也不用担心递归会把栈占满, 因为 Scheme 会自动处理尾递
归的情况. 一个简单的 0 到 10 迭代可以写成这样.
(define (iterate x)
(if (= x 10)
x
(iterate (+ x 1))))
(iterate 0)
很明显, 当我们递归调用 iterate 的时候, 我们不必保存当前的函数环境. 因为我
们递归调用完毕后就马上返回, 而不会再使用当前的环境, 这是一给尾递归的例子.
Scheme 能自动处理类似的情况甚至做一些优化, 不会浪费多余的空间, 也不会降低
效率. 所以完全可以代替循环.
当然我们有些便于循环迭代的操作, 大家可以试试自己实现他们. (当然在解释器内
部通常不会用纯 scheme 语句实现他们). 我们最常用的是 map 操作
(map (lambda (x) (+ x 1)) '(1 2 3))
运行一下这个例子, 就能理解 map 的作用了.
- 更多的数据操作
* cadr cddr caddr 之类, 就是 car 和 cdr 的组合, 大家可以一个个试. drScheme 支持到 cadddr...
* append: 将两个列表拼接在一起.